R Sidebot: How to Add an LLM Assistant to Your R Shiny Apps

.png)
Imagine a dashboard where queries and filters are applied through natural text - that’s exactly what you’ll build today!
You already know that you can build R Shiny Applications with Generative AI, but this one is quite different. The goal is not to help you generate the source code but rather to allow the end user to ask questions, and have your dashboard elements updated automatically with relevant data.
In other words, Generative AI replaces traditional dropdown menus, sliders, input fields, and other data-filtering operations. It understands the semantics of your data and can successfully manipulate it based on user input (natural language). Even better, you can use it to explain charts to remove every level of uncertainty.
After reading this article, you’ll know how to use the R Sidebot project to add Generative AI functionality to your project. We'll show you how to run the original app, and how to customize it for your dataset.
Let’s dig in!
New to Machine Learning in R? Try tidymodels, a tidyverse-like ecosystem for machine learning in R.
Table of contents:
- Why You Should (and Shouldn’t) Add an LLM to Your Shiny App
- R Sidebot: How to Get Started
- R Sidebot: How to Customize the Assistant to Work on Your Data
- Summing up R Sidebot
Why You Should (and Shouldn’t) Add an LLM to Your Shiny App
Adding an LLM to your app brings the user experience to a whole other dimension, but it’s not without its downsides. Before diving into the code, let’s first discuss some more generic pros and cons of using LLMs in your apps.
Pros of using LLMs
In terms of replacing traditional filters with an LLM in your application, there are some obvious benefits for the end user, so we’ll list a couple of them here:
- Enhanced User Experience: Apps take time to learn, even those with a superb user experience. If users can quickly ask questions in natural language, their learning curve reduces drastically when compared to navigating through numerous filters and settings. Built-in chatbots provide intuitive and interactive responses which often results in a more engaging user session.
- Easier Data Exploration: Your app or dashboard might contain some gold nuggets, but it doesn’t make a difference if the end user can’t get to them. Going through multiple filters is less user-friendly than asking a simple question like “Show me last month’s sales in Toronto” or something similar. It’s a critical win for everyone, especially for non-technical users.
- Personalized Insights: You can configure the app in such a way that user preferences matter when it comes to response formatting. For example, some might prefer to-the-point changes in data and visuals, while others might prefer all of that plus natural language explanations.
- Makes Complex Workflows Simpler: Imagine looking at your dashboard and wondering how many steps it will take to compare sales from this quarter to the previous quarter. It’s probably not something you can do in one click. With a chatbot, users can automate multi-step analyses and retrieve complex data with simple natural language commands.
- Reduces Training and Support Costs: Because chatbots are intuitive, they minimize the learning curve for new users and hence decrease (or even eliminate) the need for extensive training.
Cons of using LLMs
It’s not all sunshine and rainbows, and you also have to be aware of potential drawbacks when replacing traditional web application filters with LLMs. These are:
- Data Sharing: Your data, or at least your data scheme is shared with a third party (such as OpenAI). It might not be relevant to you for a personal pet project, but it’s almost never a good idea for enterprise projects dealing with sensitive data. You could mitigate this by self-hosting an LLM, but that comes with its own set of headaches.
- Cost: Text embedding and running communicating with LLMs isn’t free, and it definitely won’t be cheap if you have a large user base. Like in the previous item, self-hosting an embedding and chat model might be a good idea here.
- Answer Quality: LLMs are known to hallucinate, and getting around that is easier said than done. If you want every generated answer to be spot on, prepare to spend some time with prompt engineering.
- Fallback Implementation: What happens if the chatbot can’t get the data query right? Or you run out of credits? Or if internet connection fails? There are many points of failure, so it’s wise to think ahead. Maybe give your user an option to switch between a chatbot and more traditional data filtering options on the application settings page.
You now know the positive and negative sides of using LLMs in your application for data manipulation purposes. Up next, you’ll get your hands dirty with R Sidebot.
R Sidebot: How to Get Started
The R Sidebot project is available on GitHub and requires minimal intervention to get it up and running on your machine. In this section, you’ll see how it works on the default tips application, and then in the later section, you’ll see how to modify it to work on your data.
Download the GitHub repo
To start, download the source code from the official GitHub repository:
The project contains application logic and data that shows you the Sidebot in action on the tips dataset.
To get started, you should run the following command from the R console (to install dependencies):
That takes care of external R dependencies, however, the project is missing the OpenAI API key setup process, so let’s cover that next.
Setup OpenAI API key
Assuming you have an OpenAI account, head over to the API keys section in the Settings menu. Here, you’ll want to create a new API key (or reuse the one you already have):
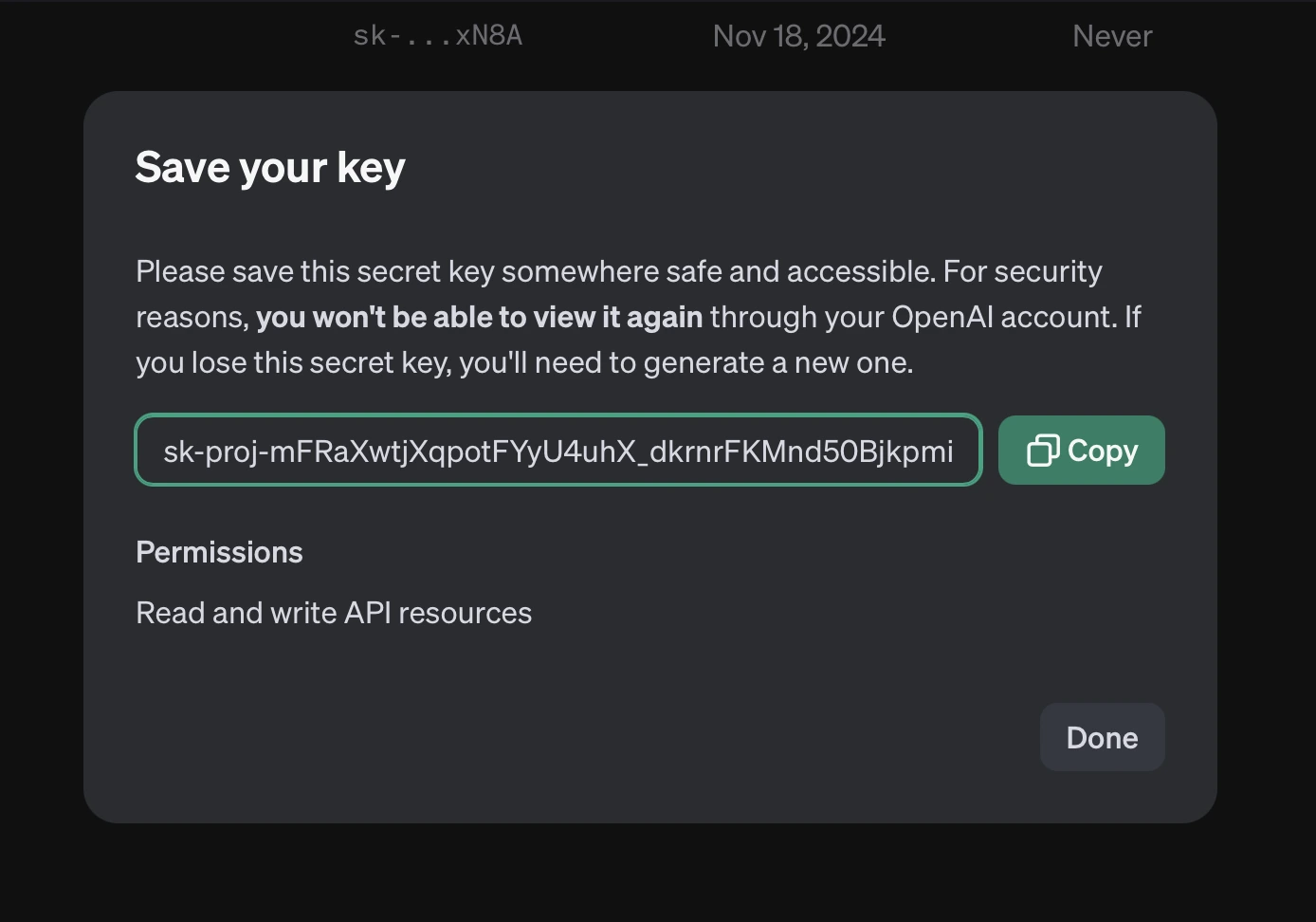
The API key is now created, so make sure to copy its value somewhere safe - you won’t be able to see it from the OpenAI settings page in the future:
Now, assuming you’ve already opened the downloaded Sidebot project in RStudio or Positron, create an `.Renviron` file and declare an environment variable named `OPENAI_API_KEY`. Paste your key after it, separated by the `=` sign:
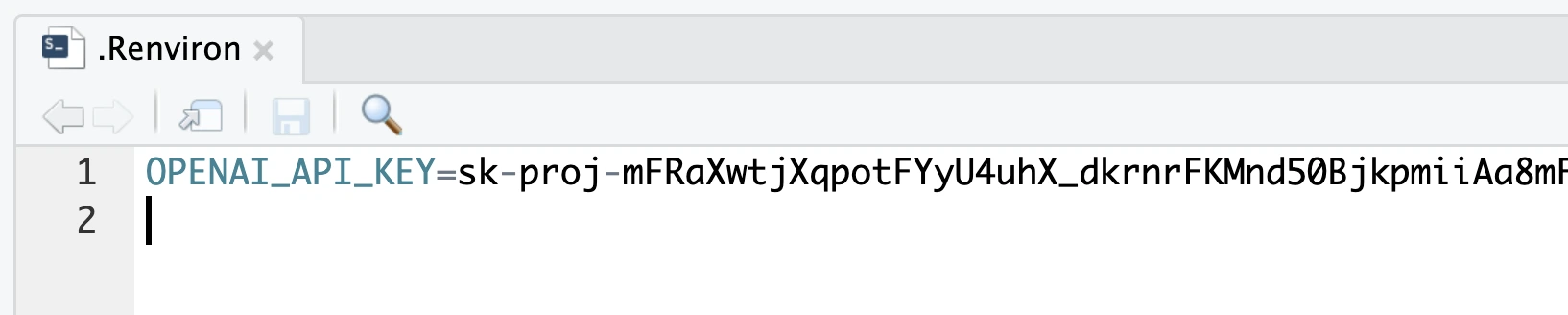
You could set the environment variable in some different manner, but `.Renviron` file is among the most practical options. Just don’t forget to add it to `.gitignore`.
OpenAI quota error - How to fix it
You can now start the Shiny application, and the default data and charts will be rendered correctly:
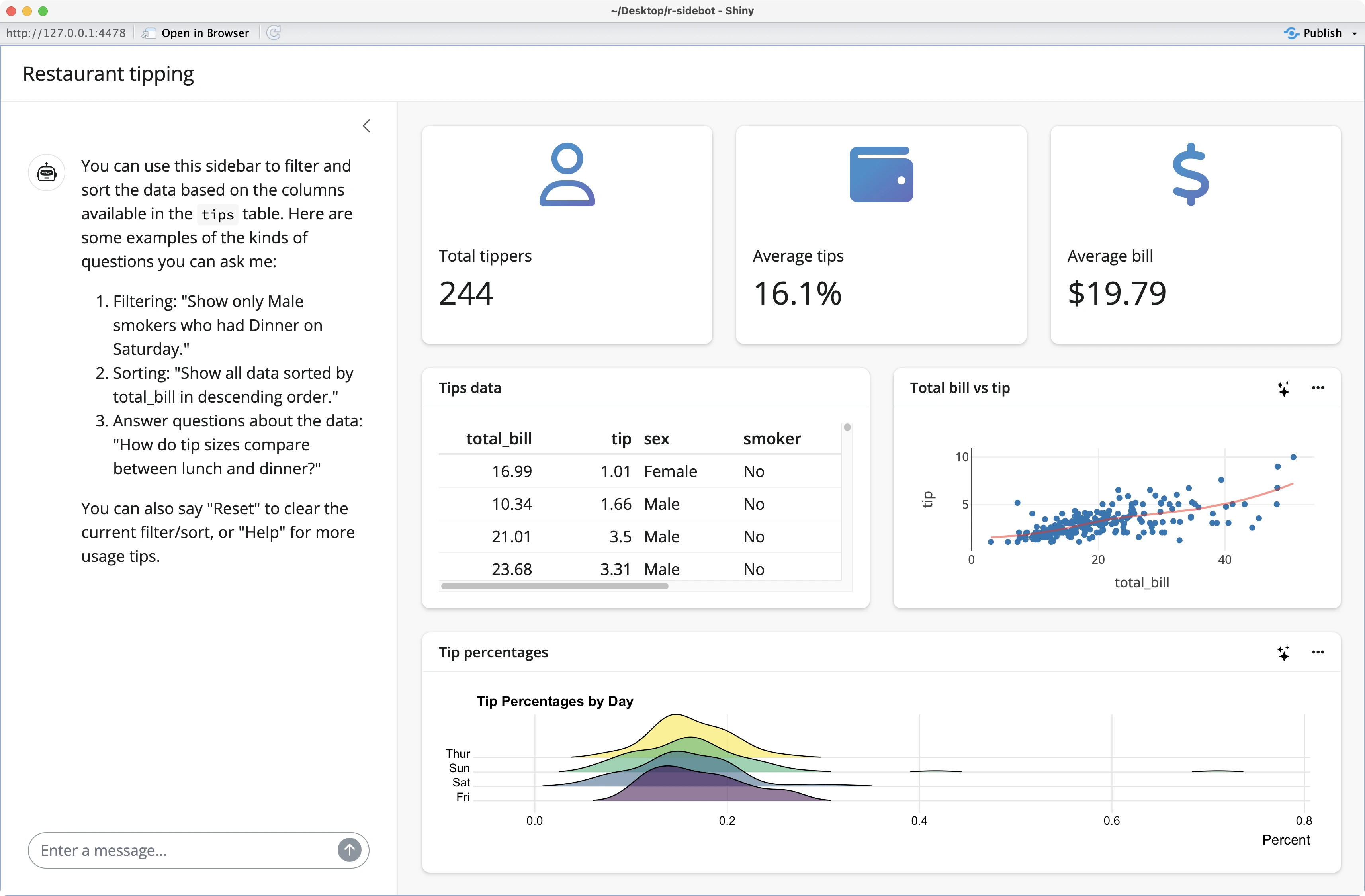
You can even start asking questions in the sidebar, as you can see from our example below:
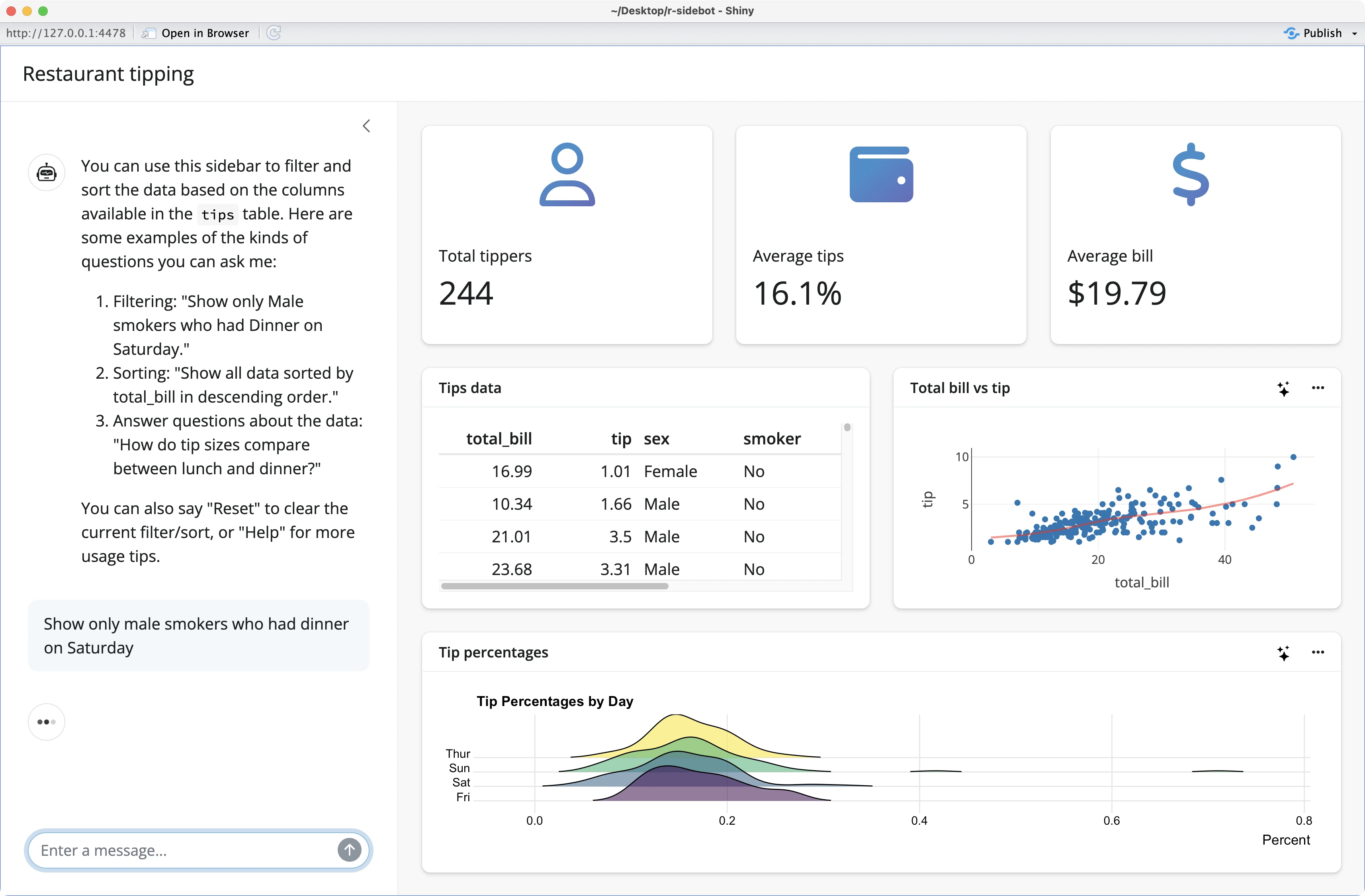
However, if you’re on a fresh OpenAI account, you’ll likely run into the `HTTP 429 Too Many Requests` error. It happens because your account has no credits:
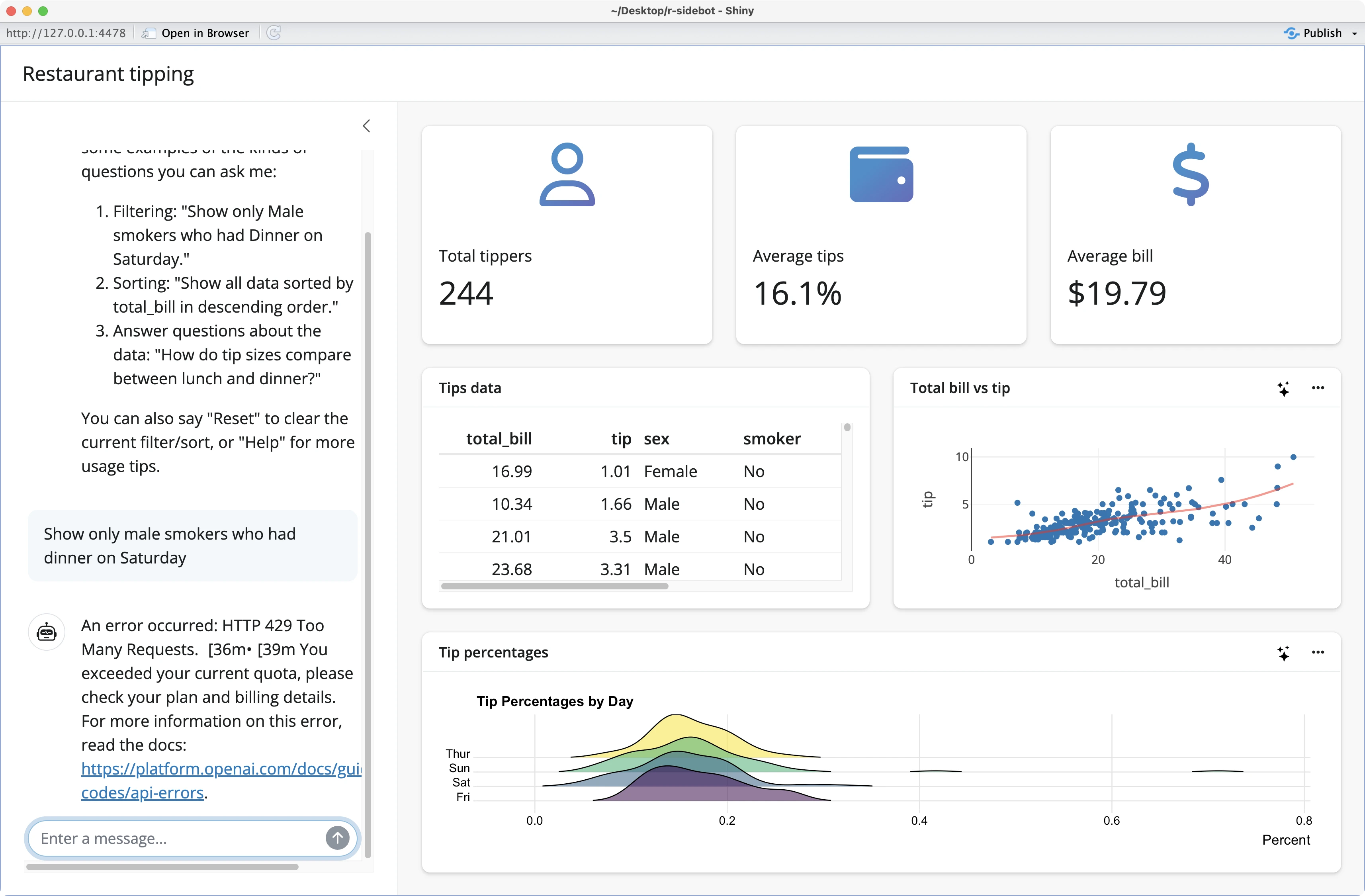
To fix this, you have to go back to the OpenAI Settings page, add a Billing method, and add funds to your account. The minimum amount as of November 2024 is USD 5 (before taxes).
Once that’s out of the way, you’ll see available credits in your account:
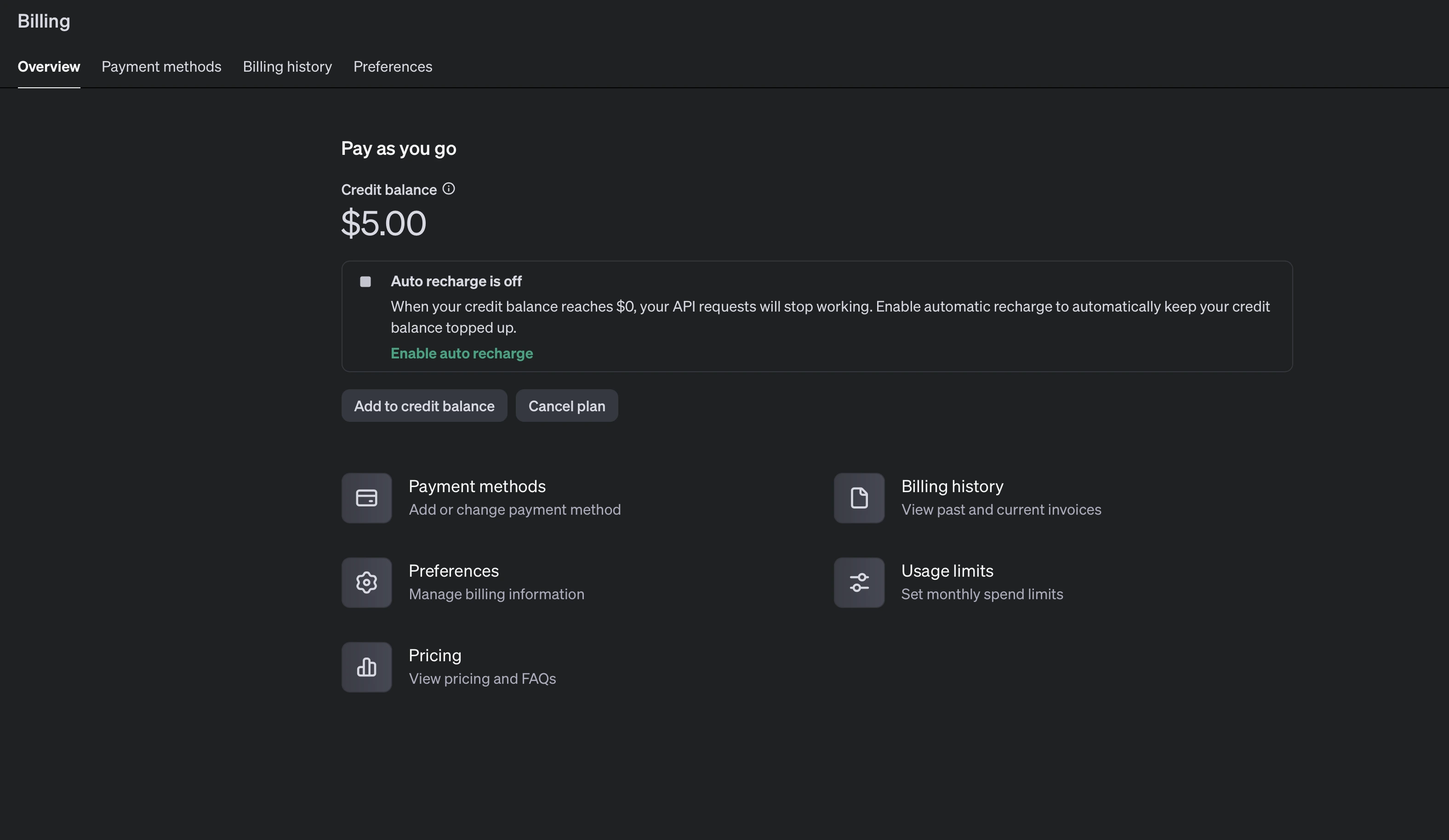
Hopefully, this should fix the `HTTP 429` error.
Response streaming error - How to fix it
If you restart your app, you’ll see another error message after submitting your question:
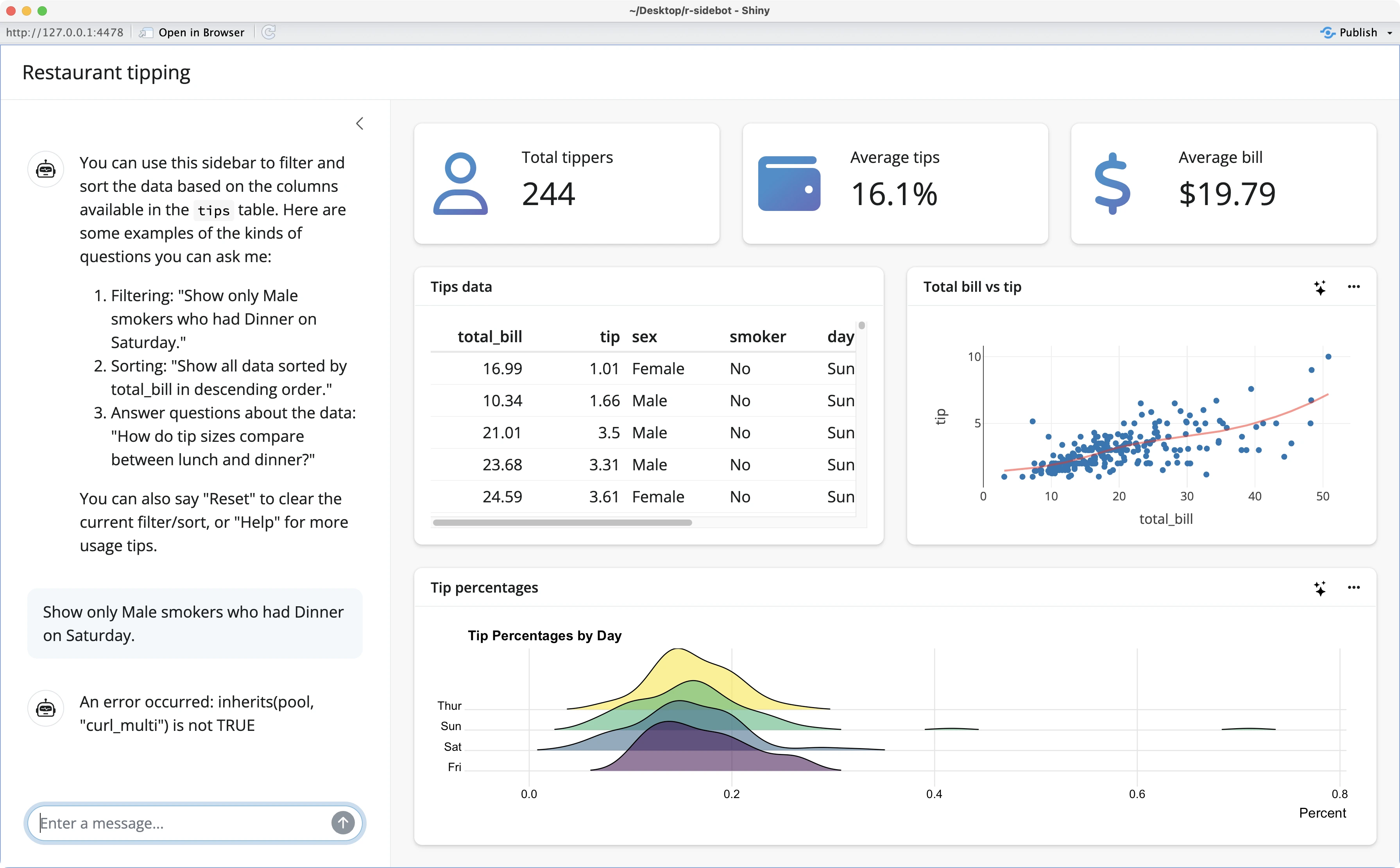
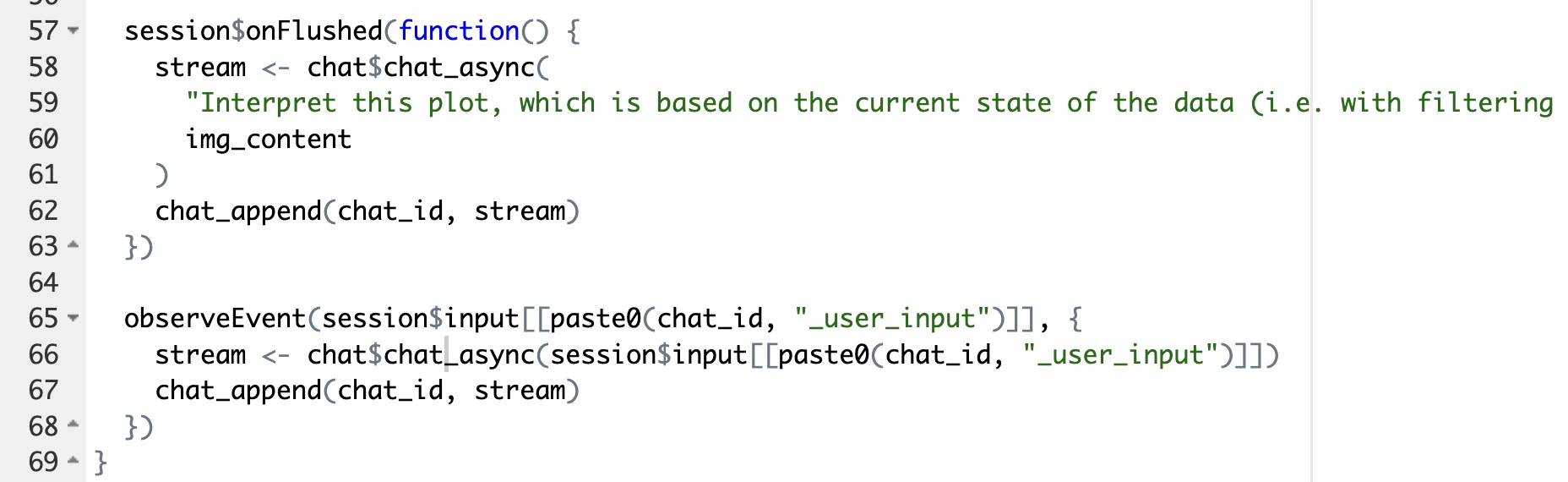
This one is a bit trickier to solve, but it boils down to Sidebot using a buggy `stream_async()` method to get the response back to the user. In `app.R` on line 355, swap it for the `chat_async()` method instead:
This is what your code should look like after the change:
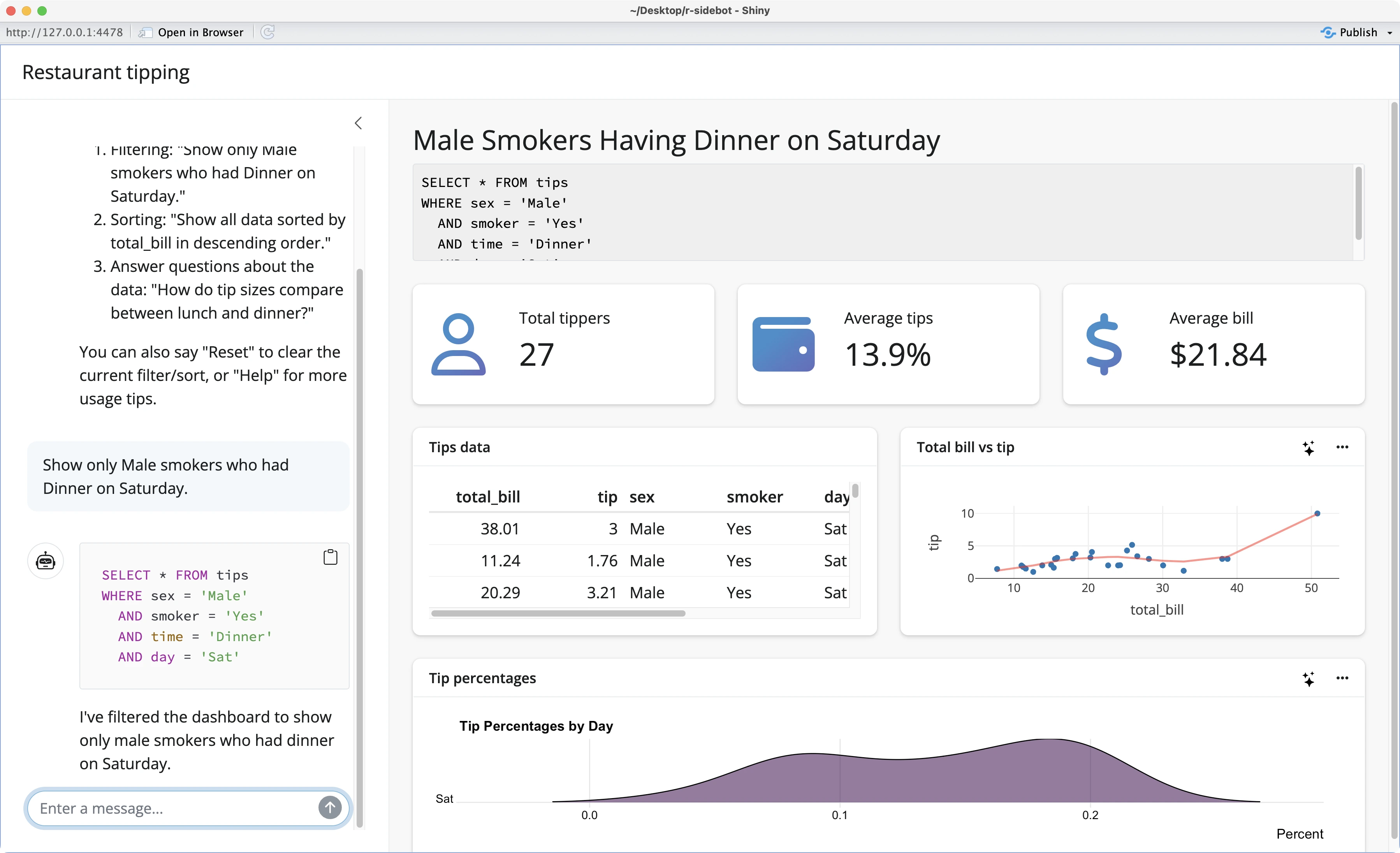
And now finally, you’ll see the app updated after submitting your query through the chat interface:
Both charts in the dashboard have a familiar stars icon often used to represent AI features. When you click on it, you should see AI insights about the current charts.
Unfortunately, this doesn’t happen, and a familiar error message is displayed instead:
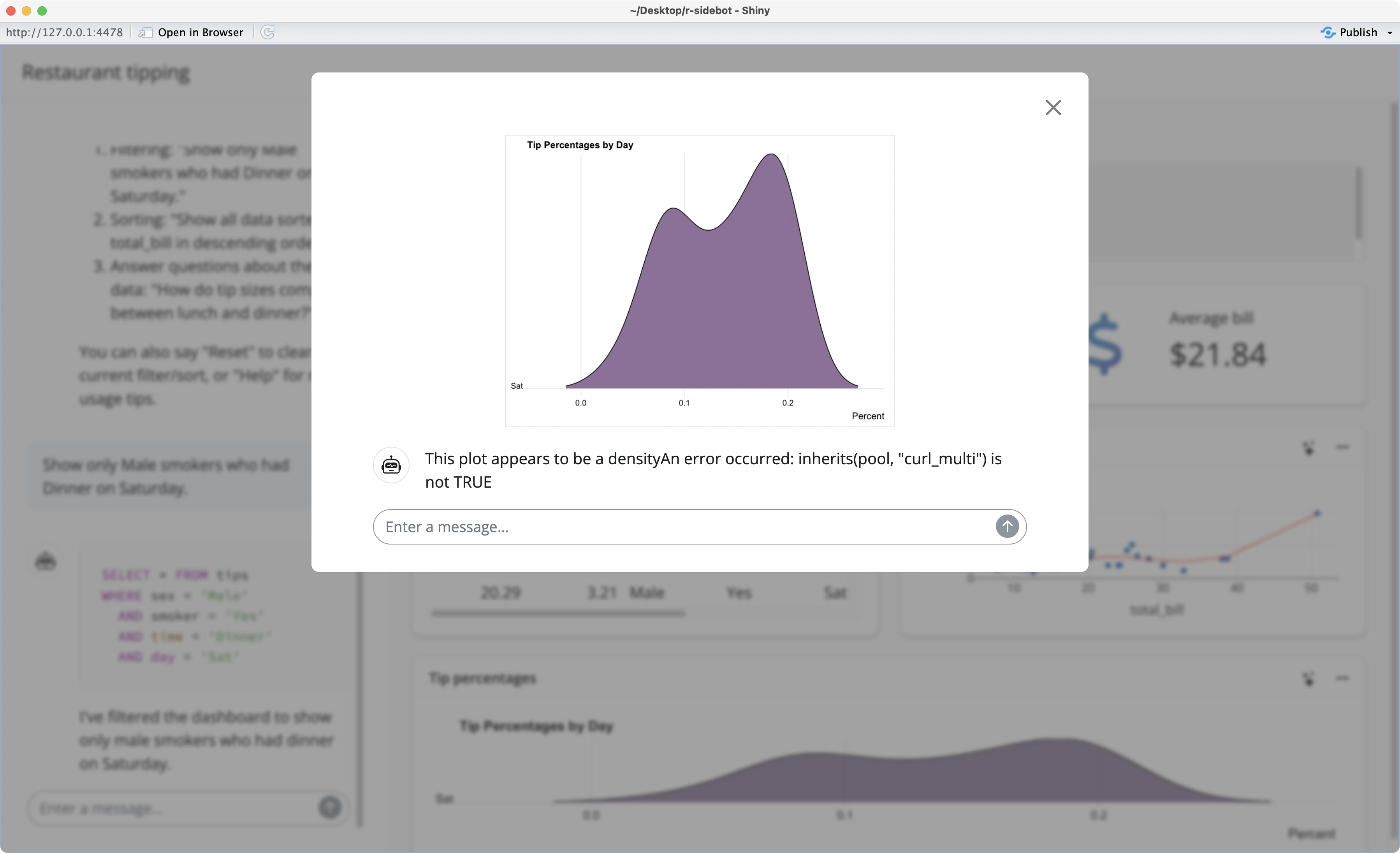
You already know how to fix it - replace `stream_async()` with `chat_async()` in two places in `R/explain-plot.R`:
This is what your code should look like after the change:
Restart the app once more, and you’ll be presented with a large text block of plot explanations:
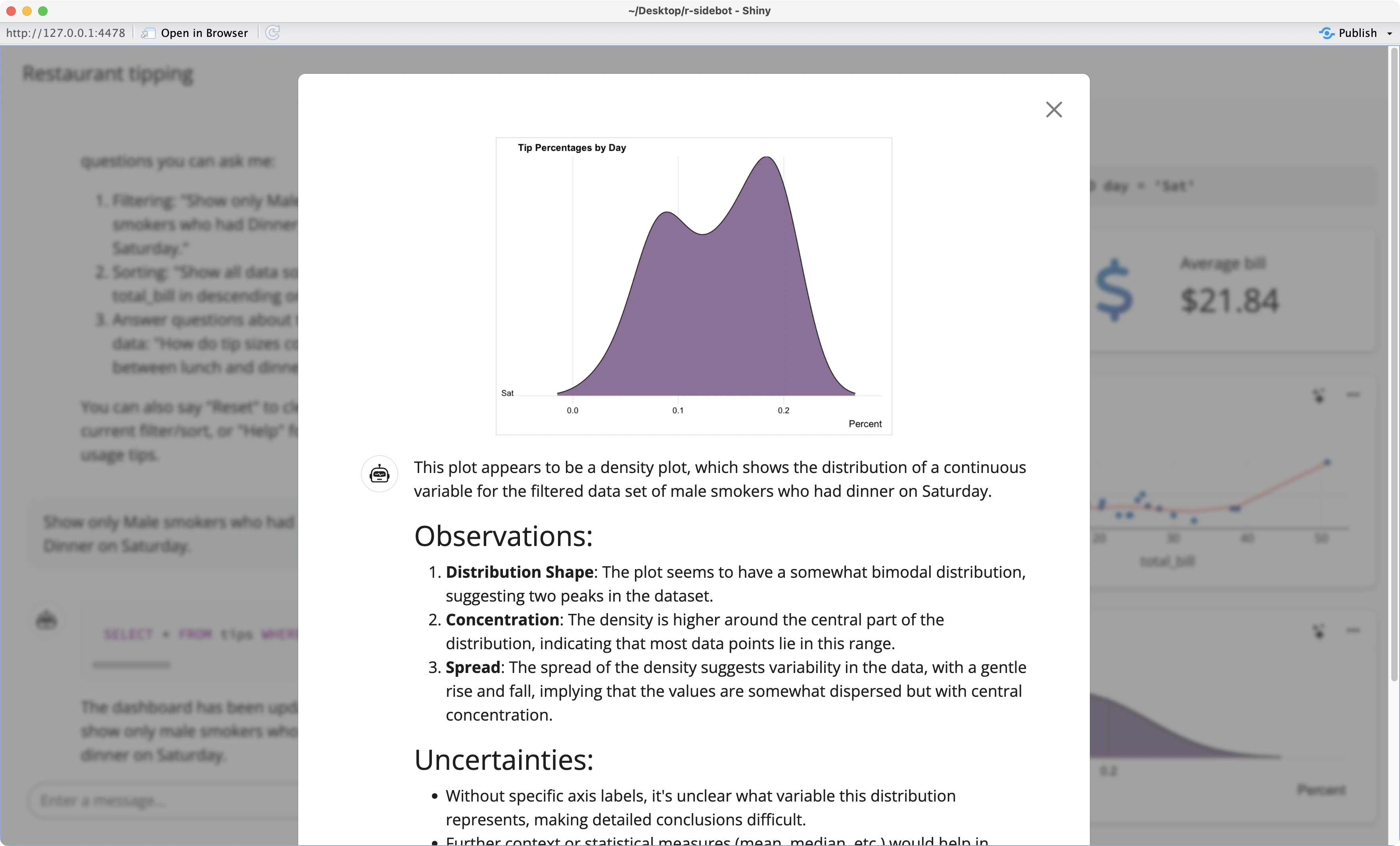
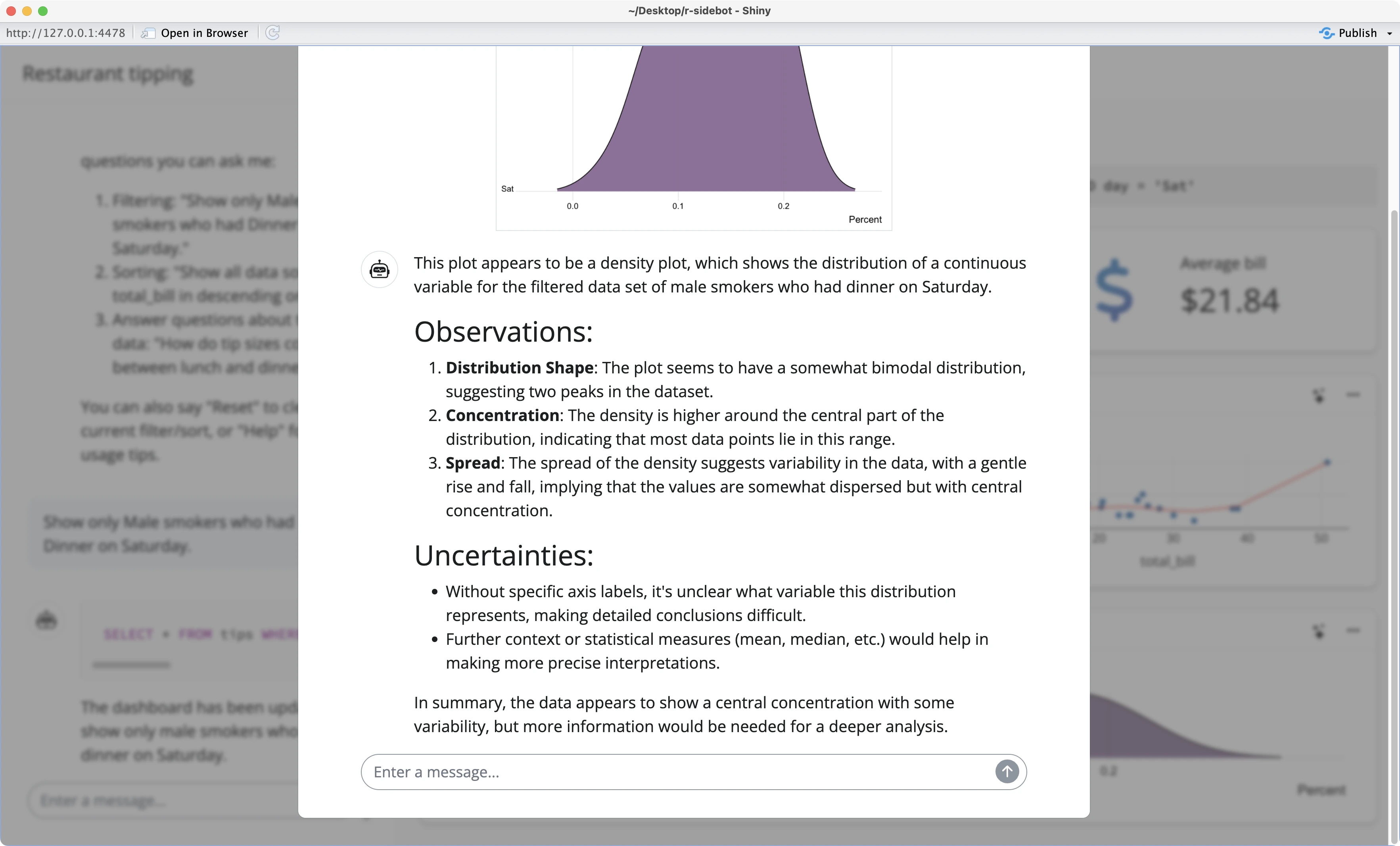
The R Sidebot app is now working as advertised on the tips dataset. Up next, you’ll see how to tweak the app so it works on other datasets as well.
R Sidebot: How to Customize the Assistant to Work on Your Data
In this section, you’ll see what it takes to customize R Sidebot to work on the Iris dataset.
Download the dataset
Start by downloading the dataset from a provided link. Store it as a CSV file in the project folder:
Convert CSV to DuckDB
Once downloaded, you’ll want to slightly tweak the `scripts/setup.R` file and run it so that the CSV file is converted to DuckDB. This is required so the Sidebot can generate SQL queries:
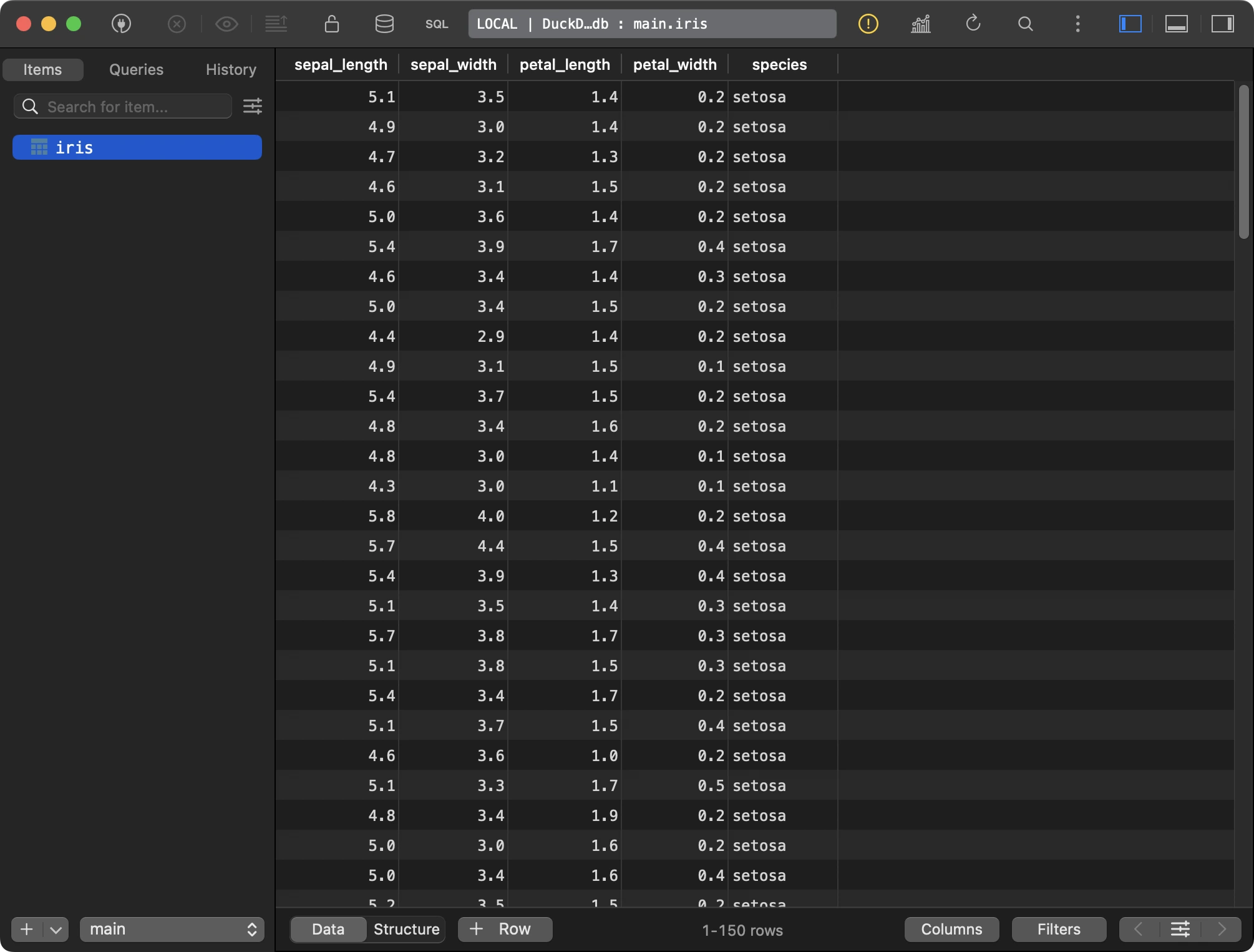
If you open the DuckDB file with a tool like TablePlus, you’ll see the dataset is stored in the `iris` table:
Customize Markdown files
You might have noticed two markdown files in the project directory - `greeting.md` and `prompt.md`. We don’t want to overwrite them, so create two new files - `greetings_iris.md` and `prompt_iris.md`.
The latter is a direct copy, while the prior needs some modifications. In short, it represents the text shown to the user in the sidebar. Make sure to include helpful instructions on how to use the chatbot:
The `prompt.md` file serves as a system prompt, and you can just copy it to a new file.
Customize R scripts
Now inside `explain-plot.R`, you want to make sure you’re using the `chat_async()` method instead of `stream_async()`. If you’ve followed the previous section, no change is required here:
Customize app.R
And finally, let’s modify the `app.R` file. Here are the modifications we’ve made:
- Load the `iris.duckdb` file.
- Point to the newly created `greetings_iris.md` file for the sidebar contents.
- Inside UI value boxes, tweak the top 3 cards to show a number of rows, average petal length, and average petal width. Output names are also updated, so this will have to be reflected in the server.
- Remove the area plot.
- Update the `server()` function to point to new data and update reactive data for the 3 tweaked UI components.
- Remove area plot logic from the `server()` function.
It’s quite a bit of work, no arguing there. This is our final version of the `app.R` file:
Let’s see what the app looks like next.
Application demonstration
The app is much simpler after the updates since we have fewer UI components:
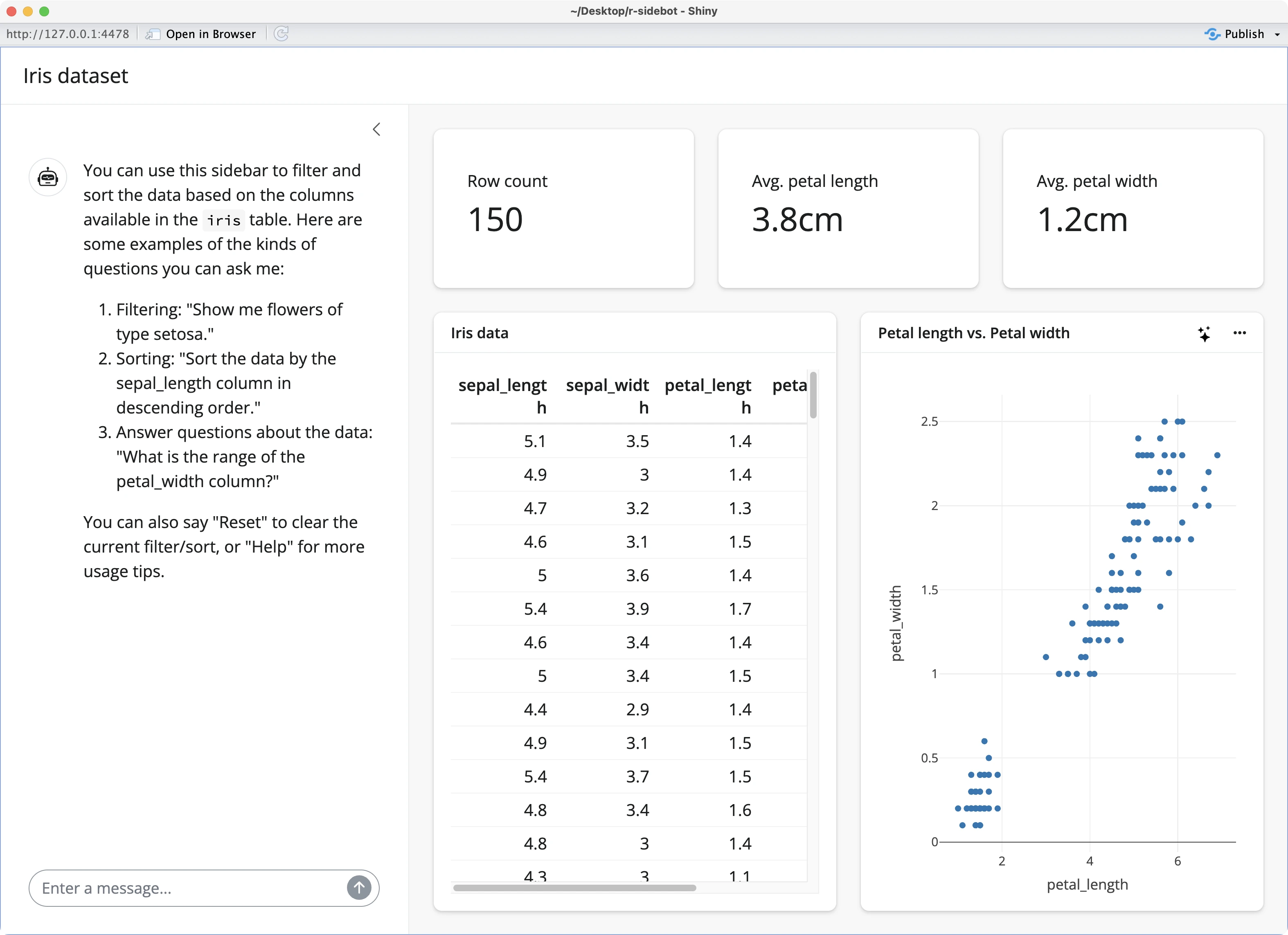
But overall, the filtering operations applied through natural text work like a charm:
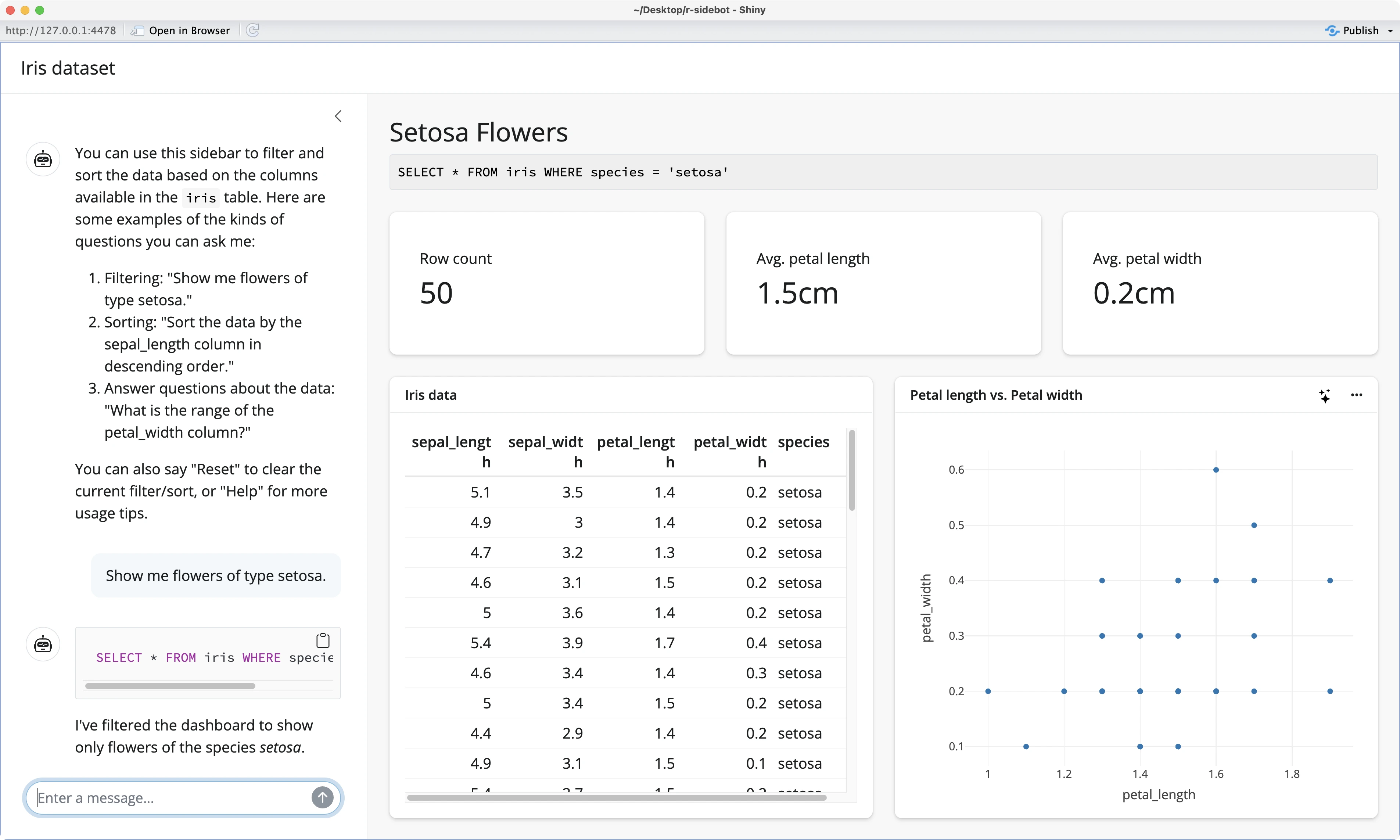
And that’s it - you now know how to customize R Sidebot to work on your data!
Let’s make a brief recap next.
Summing up R Sidebot
Generative AI is here to stay.
Projects like R Sidebot perfectly demonstrate how much LLMs have matured over the years and how the amount of friction of using LLMs in your apps has decreased over time. Sure, the underlying packages such as elmer and shinychat are still experimental, but there’s no doubt in what the future holds.
At Applison, we’re proud to say that we’we successfully adopted LLMs in customer projects and in-house products. For example, we’be built Extractable, a tool that uses GPT to extract data from uploaded documents and transform it into standardized tables. We’ve also developed a Text2Graph application that allows you to transform your datasets into beautiful visualizations through natural text.
If your company can benefit from Large Language Models, feel free to reach out and tell us about your idea.
What are your thoughts on R Sidebot and LLMs as a replacement for traditional filters in apps and dashboards? Join our Slack community and let us know.
It’s one thing to write an R Shiny app, but deploying it comes with its own set of challenges. Read our 5 recommended deployment options for individuals and enterprises.
.png)



.png)
