Optimizing R/Shiny App Performance with Advanced Caching Techniques

.png)
The concept of caching refers to the practice of storing frequently accessed data in a temporary storage area (the cache) to speed up future data retrievals. By avoiding redundant computations or database queries, caching enhances application performance and efficiency.
In an R Shiny app, caching can be implemented to store the results of expensive computations or data fetch operations.
Need tips on how to build blazing-fast Shiny applications? We’ve got you covered in this detailed blog post.
For instance, if a Shiny app performs complex data analysis or retrieves large datasets, caching those results means that subsequent users or sessions can access the pre-computed data without repeating the intensive tasks, leading to faster response times and reduced server load.
In this post, we’ll explore how caching works in Shiny apps, the various levels of caching, and implementation strategies to maximize efficiency. Whether you’re working on small-scale apps or complex, distributed systems, these insights will help you take your Shiny app to the next level.
How Caching Can Work on Different Levels of Your System
Depending on the situation and the needs, several methods can be used to implement caching in a shiny app. The methods below are gradually more complex but increasingly more powerful.
The cache can be set for a session or for all the app users, up to several applications, if needed.
Here are the different types of cache levels that can be used:
- Cache per Session
This level of caching is specific to each user session. Cached data is stored separately for each user, ensuring that one user's data does not interfere with another's. This is useful for user-specific computations or data that should remain isolated across sessions.
- Cache per App
This caching level is shared across all sessions within the same Shiny application instance. All users and sessions can access the same cached data, making it useful for computations or data that are common across all users but need to be recomputed when the app restarts.
- Global Cache
This level involves sharing cached data across multiple instances of the Shiny app, possibly running on different servers or in a load-balanced environment. The cache is shared across all instances of the app, making it suitable for distributed environments.
- Persistent Cache
Persistent caching involves storing cached data in a way that it persists even after the app restarts. This can be achieved by storing the cache on disk or using a persistent storage backend like a database. It's ideal for caching large datasets or results that don't need to be recalculated between app sessions.
Reactive Expressions (Base Shiny Caching)
Reactive expressions (reactive(), reactiveVal(), reactiveValues()) inherently provide a basic form of caching.
They store their outputs and only re-execute when their reactive dependencies change. This means that if the inputs remain the same, the stored result is reused without recomputation.
Example:
reactive_data <- reactive({
# Expensive computation here
})
In-Memory Caching with bindCache
Introduced in Shiny 1.6.0, bindCache() allows developers to cache the results of reactive expressions or render functions based on specified keys. The cached data is stored in memory, leading to faster retrieval times for repeated computations with the same inputs. By default the scope of the cache is for the entire application. For the cache to be independant between users cache = “session” argument needs to be passed.
Example:
output$plot <- renderPlot({
# Plot generation code
}) %>% bindCache(input$some_input)
File System Caching with bindCache and cachem
While bindCache() defaults to in-memory caching, it can be configured to use file system caching. By setting shinyOptions(cache = cachem::cache_disk("path/to/cache")), cached results are stored on the disk. This approach is beneficial for large datasets or when the application restarts, ensuring cached results persist across sessions.
Packages Involved:
- cachem: Provides the caching backend.
- memoise: Often used in conjunction to memoize functions, though bindCache() handles caching internally without direct reliance on memoise.
Example:
shinyOptions(cache = cachem::cache_disk("./cache_dir"))
output$plot <- renderPlot({
# Plot generation code
}) %>% bindCache(input$some_input)
Distributed Caching with Redis (redux Package and Custom Wrapper)
For applications that require shared caching across multiple R sessions or servers, Redis provides a powerful solution.
Redis allows caching data in a centralized location, enabling different Shiny instances (e.g., on different servers) to access the same cache. This is particularly useful in load-balanced environments or when scaling Shiny apps.
Implementation: A custom caching class using the redux package and R6 is created to interact with Redis. This class can be configured to handle caching with a specific namespace, and can control Redis's memory usage and cache eviction policies (e.g., Least Recently Used or LRU).
Packages Involved:
- redux: Provides an interface to interact with a Redis server.
- R6: Used to create the custom Redis cache class.
Example Implementation taken from https://shiny.posit.co/r/articles/improve/caching/ :
library(shiny)
library(redux)
library(R6)
# Define a RedisCache class using R6
RedisCache <- R6Class("RedisCache",
public = list(
initialize = function(..., namespace = NULL) {
private$r <- redux::hiredis(...)
# Configure Redis as a cache with a 20 MB capacity
private$r$CONFIG_SET("maxmemory", "20mb")
private$r$CONFIG_SET("maxmemory-policy", "allkeys-lru")
private$namespace <- namespace
},
get = function(key) {
key <- paste0(private$namespace, "-", key)
s_value <- private$r$GET(key)
if (is.null(s_value)) {
return(structure(list(), class = "key_missing"))
}
unserialize(s_value)
},
set = function(key, value) {
key <- paste0(private$namespace, "-", key)
s_value <- serialize(value, NULL)
private$r$SET(key, s_value)
}
),
private = list(
r = NULL,
namespace = NULL
)
)
Usage in Shiny App: Once configured, the Redis cache can be used with bindCache() or any custom caching logic. The RedisCache object manages the retrieval and storage of cached items, ensuring efficient caching across different Shiny sessions.
Example Usage with bindCache:
# Configure Shiny to use the Redis cache
shinyOptions(cache = RedisCache$new(namespace = "myapp"))
output$plot <- renderPlot({
# Plot generation code
}) %>% bindCache(input$some_input)
You’ll also need to have redis running locally, the best method is via Docker and the command:
docker run --rm --name redisbank -d -p 6379:6379 redis
Session-Specific Caching with session$cache
This feature allows caching data specific to a user's session. It's beneficial when different users might have different data scopes, and caching should not overlap. Each session can have its own cache, ensuring data privacy and relevance.
Usage Example:
server <- function(input, output, session) {
session$cache <- cachem::cache_mem()
output$plot <- renderPlot({
# Plot generation code
}) %>% bindCache(input$some_input, cache = session$cache)
}
Database Caching
Although not a native feature of Shiny, developers can implement caching mechanisms using databases like PostgreSQL or MongoDB. This is especially useful for large-scale applications where persistent and queryable caching is required.
Packages Involved: Depends on the database (e.g., RPostgres, RMongo).
Usage Example: Implementation varies based on specific requirements and database choice.
Learn how to connect R and R Shiny to the Postgres database. We cover what you need to know in this blog post.
About plots:
When caching plots, it is recommended to use fixed dimensions for the plot to maximize the chances of the cache being used, otherwise a new version of the same graph will be stored for every combination of dimensions that the users have on their screen depending on their monitor, browser window size etc.
Profiling helps you figure out which parts of your code are slowing things down. Explore our guide to profiling R and R/Shiny code to learn more.
Implementation (Complete Examples of an App Using All Variations of Caching)
We will showcase the different caching tools and strategies by using the Bioinformatics Manhattan plot.
A Manhattan plot is a type of scatter plot used in bioinformatics, particularly in genome-wide association studies (GWAS), to display the association between genetic variants and a particular trait or disease. Each point on the plot represents a single nucleotide polymorphism (SNP), with its position along the genome on the x-axis and its significance (usually as the negative logarithm of the p-value) on the y-axis. This visualization helps to identify regions of the genome that are significantly associated with the trait being studied.
Manhattan plots are crucial for interpreting GWAS results because they can highlight genetic loci that may contribute to complex diseases. The datasets involved in GWAS are typically massive, often containing millions of SNPs and data from thousands of individuals, making effective visualization tools like Manhattan plots essential for meaningful analysis.
Generating data
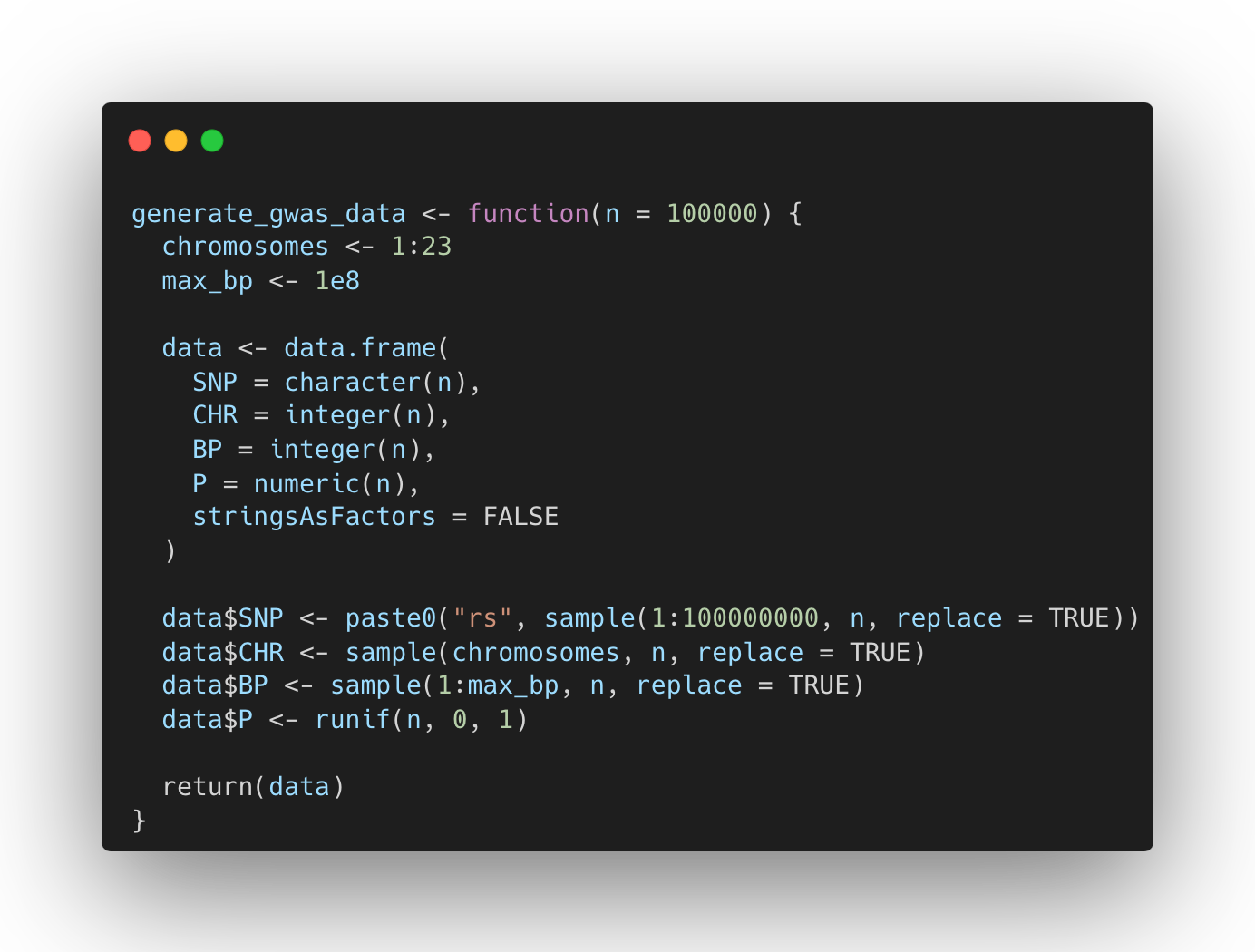
The function generate_gwas_data creates a dataset with a specified number of genetic variants (SNPs), randomly assigning each SNP a chromosome (CHR), a base pair position (BP), and a p-value (P). The SNP identifiers are simulated by generating random numbers prefixed with "rs". The random assignment of these values mimics the distribution of SNPs across the genome and their corresponding significance levels, which are essential for creating a representative Manhattan plot.
Plotting
.png)
The plotting strategy used in the create_manhattan_plot function focuses on visualizing GWAS data in a Manhattan plot by arranging SNPs along the genome and displaying their significance. The function first calculates cumulative base pair positions (BPcum) across chromosomes to position SNPs accurately along the x-axis. This allows for a continuous representation of SNPs across all chromosomes. The data is then grouped and summarized to calculate chromosome-specific lengths and their cumulative totals, which are used to adjust the SNP positions. The plot itself is generated using ggplot2, where SNPs are plotted with their cumulative positions on the x-axis and the negative logarithm of their p-values on the y-axis. Chromosomes are color-coded alternately for visual clarity, and custom axis labels are created to represent the center of each chromosome.
Simple Shiny App With Only Reactives
We will start with a simple shiny app that only uses reactives to generate the GWAS data and make the Manhattan plot.
.png)
Shiny App With Session Level Memory Cache
Using a session level memory cache, this will allow each user to cache the plot they’ve just seen, this way they don’t have to wait again but the cache is lost once they leave the app and other users won’t benefit from it.
.png)
As you can see in the code, this was as simple as adding bindCache with the input that it depends from chained to the reactive and render plot.
Shiny App With App Level Caching on Disk
We now tell Shiny to use the disk to cache the data via shinyOptions. We also explicitly set the cache scope in bindCache as “ap,” but it’s not mandatory as this is the default mode.
.png)
This will allow reuse of the cached data and plots between sessions, even if the application is restarted and between users.
This is the minimum required to start using cache warming tools.
Shiny App With App Level Cache in Redis
This is a more complex implementation of the version seen before as instead of using the disk to store the files, we will use Redis to store the cached data and plots.
Note that the current example doesn’t include any security to access Redis so either add username/password authentication or ensure that only your app can access Redis.
.png)
.png)
Take Things to the Next Level: Cache Warming
The issue with caching is that someone first needs to wait for the plot or the data to be computed before it is cached and available for the following users.
The concept of cache warming aims to address that by ensuring that the cache is always ready for the first user. This can be performed for cases where we have a set refresh cycle for the data displayed.
It then becomes possible to use shinyloadtest or testServer to simulate interactions with the app right after the cache has been cleared.
Shiny app with app level cache in redis with cache warming
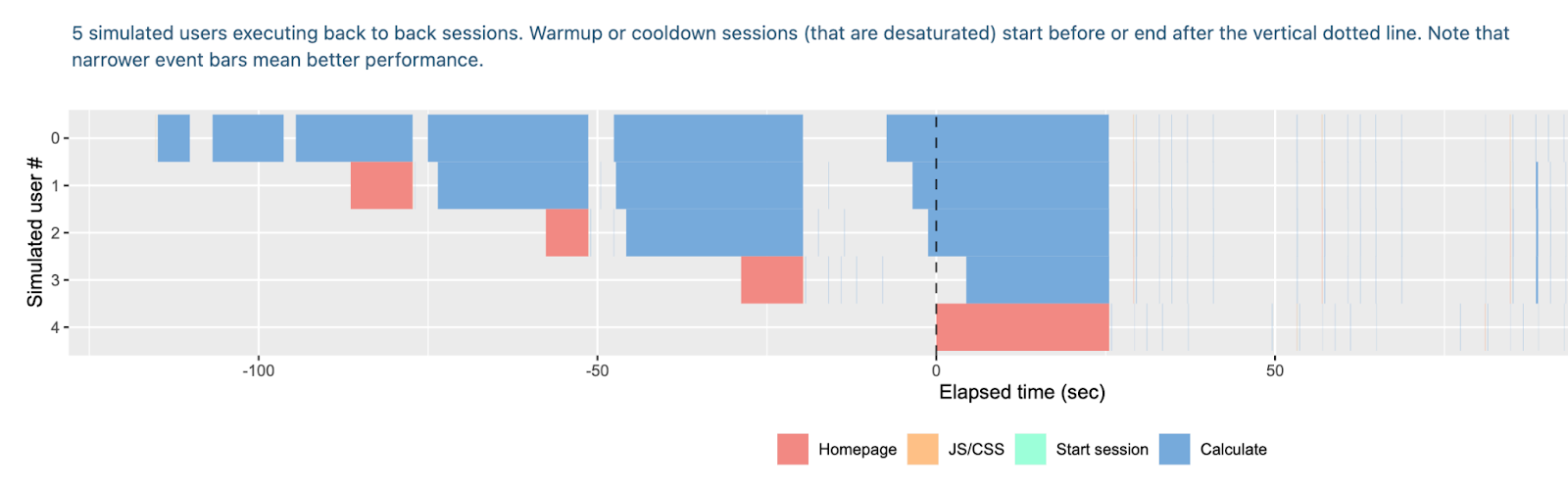
Without hotcache:
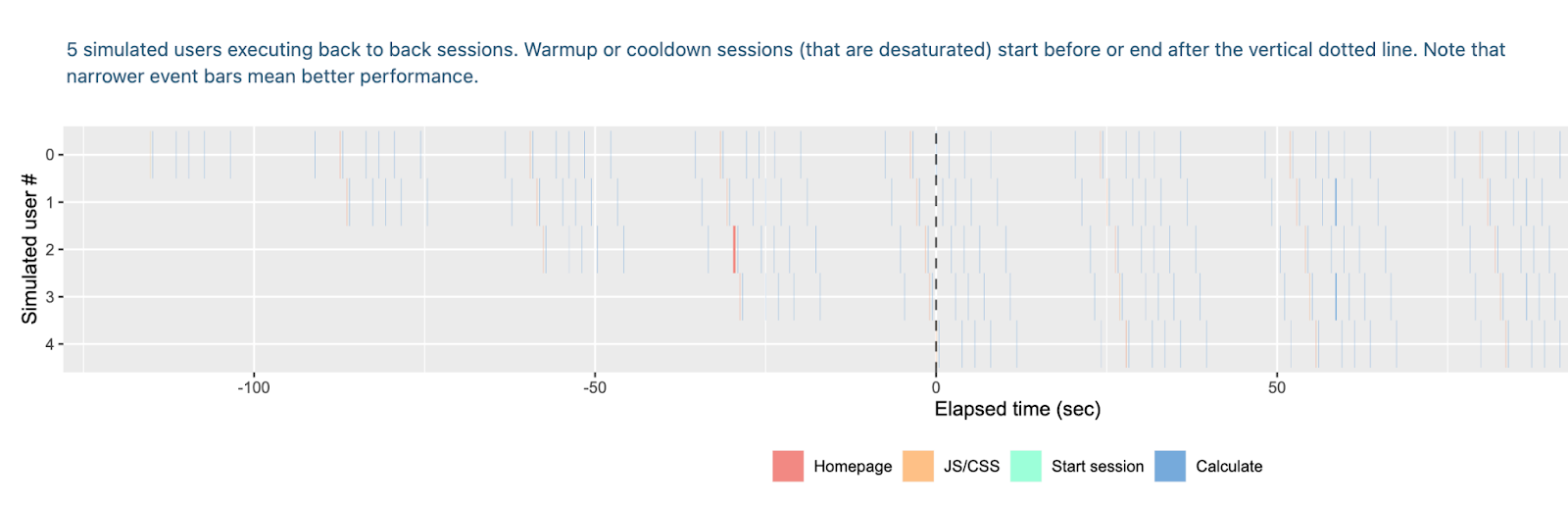
With hotcache:
We see that the first user on the app without the hot cache is having a terrible experience as all the plots take a long time to display. Users joining afterwards are also stuck because async hasn’t been implemented here and so they need to wait for the plot of user 1 to be completed before they can even reach the homepage.
Meanwhile with the hot cache, all the users are served instantaneously and there’s no waiting time for anyone.
Ready to optimize your Shiny app performance? Explore efficient coding practices in our comprehensive guide.
Summing Up Advanced Caching Techniques
Implementing caching in R Shiny apps is crucial for delivering a seamless user experience, especially for computationally intensive applications. From session-specific to distributed global caching, each level provides unique benefits tailored to your app's needs.
Resources
- Code for Manhattan plot inspired from https://r-graph-gallery.com/101_Manhattan_plot.html
- https://shiny.posit.co/r/articles/improve/caching/
- https://shiny.posit.co/r/articles/improve/server-function-testing/
- https://rstudio.github.io/shinyloadtest/
Our ebook guides you through best practices in code collaboration, project management, and workflow optimization tailored for R/Shiny teams. Download the Level Up Your R/Shiny Team Skills ebook here.
.png)

.png)

